Assessing AI-Powered OCR Tools For Chinese Texts: A Case Study With The Chinese Times

By: Francesca Brzezicki, Heritage Engagement Officer and Mary Zheng, Application Developer
https://doi.org/10.82389/n6s5-9568
In a rapidly evolving environment where artificial intelligence (AI) is changing how people interact with digital collections and facilitating new tools to support them, CRKN has been investigating how AI-powered workflows can improve the Canadiana Collections and Infrastructure.
Our work with AI tools in the collections began in 2023, when we launched a pilot project to transcribe a set of handwritten materials in the Héritage Collection. Then, in 2025, we added the Chinese Times newspaper to the Canadiana Collection. With 23,000 issues printed in traditional Chinese characters, the Chinese Times presented a unique challenge for our optical character recognition (OCR) software and an ideal opportunity to see if new technologies can improve access to this popular collection.
Introducing Paddle
While CRKN’s standard commercial OCR tool—ABBYY FineReader Server 14—can process Chinese, we wanted to see if an open source, AI-based tool could meet or exceed ABBYY’s capabilities.
That’s when CRKN’s Application Developer Mary Zheng identified Paddle, a tool that performed well with Traditional Chinese characters and displayed strong performance across multiple metrics, including:
- Text Score, which measures the accuracy of text recognition results
- Formula Score, which measures the accuracy of mathematical formula recognition, which is important for scientific texts
- Reading Order Score, which evaluates whether the predicted reading sequence of text blocks matches the expected reading order of humans
- Table TEDS (Tree-Edit-Distance-based Similarity), which measures the quality of extracted table data, ensuring it matches the original table accurately.
In addition, Paddle is active in terms of technological innovation and supports 109 languages, making it highly suitable for processing collections with diverse languages such as the Canadiana Collections.
The Paddle suite contains multiple models for different OCR use cases. In CRKN’s case, we require not only multi-scenario and multi-type text recognition, but also layout analysis to detect and extract elements such as text blocks, titles, paragraphs, images, tables, and other layout components. Therefore, we selected the model PP-StructureV3 for testing.
Testing Paddle and ABBYY
Search queries in the Canadiana Collections need to perform across a variety of texts and frequently involve names, events, and organizations. To capture these requirements, Mary, alongside John Loitzenbauer, Digitization Technical Specialist and Brittny Lapierre, Manager of Development, designed nine types of test cases:
- Personal name recognition
- Popular Event recognition (for example, “Chernobyl nuclear disaster”)
- Organization name recognition
- Combined event queries (for example, “economic growth” and “presidential election”)
- Text recognition in advertisement images
- Rare character recognition
- Paragraph segmentation accuracy
- Correct reading order
- Sentence completeness
Both manual testing and comparative testing were used to evaluate Paddle and ABBYY. For manual testing, a text sample from the Chinese Times was randomly selected. This sample had already been processed by ABBYY, producing corresponding OCR output. During the ABBYY evaluation, staff reviewed each line of text in the OCR output and traced it back to the original newspaper source, verifying whether each line was semantically clear and measuring the proportion of correctly recognized characters relative to the total number of characters. The sample was then processed with Paddle and evaluated using the same procedure.

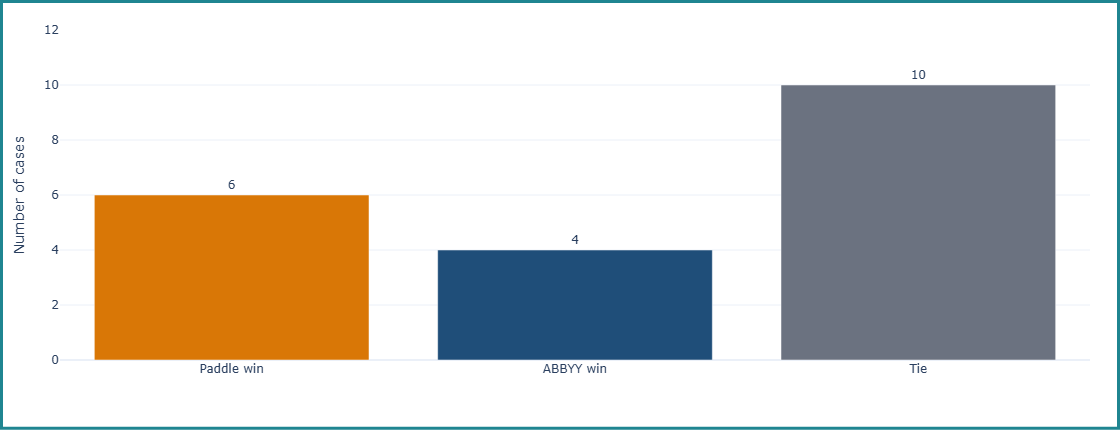
For comparative testing, the same text sample was processed with Paddle and ABBYY. Staff then reviewed the output, checking whether each sentence could be correctly identified in both the ABBYY-generated text and the Paddle-generated text. The results showed that Paddle performs comparably to ABBYY, particularly in terms of layout analysis and overall text readability, although each tool demonstrates different strengths in specific aspects of OCR performance.
Different Tools, Different Strengths
In complex layouts such as historical Chinese newspapers—where the reading order of the main text and headlines is often inconsistent—Paddle excels at detecting page layout, allowing it to correctly determine which sentence belongs to which paragraph, and which paragraph belongs to which article. However, when processing the Chinese Times, ABBYY tended to mix paragraphs from different articles together, making the text harder to read and less coherent, especially when incorrect or garbled characters are included within the sentences. ABBYY also sometimes struggled with artistic typefaces, like those found in newspaper titles or advertisements.
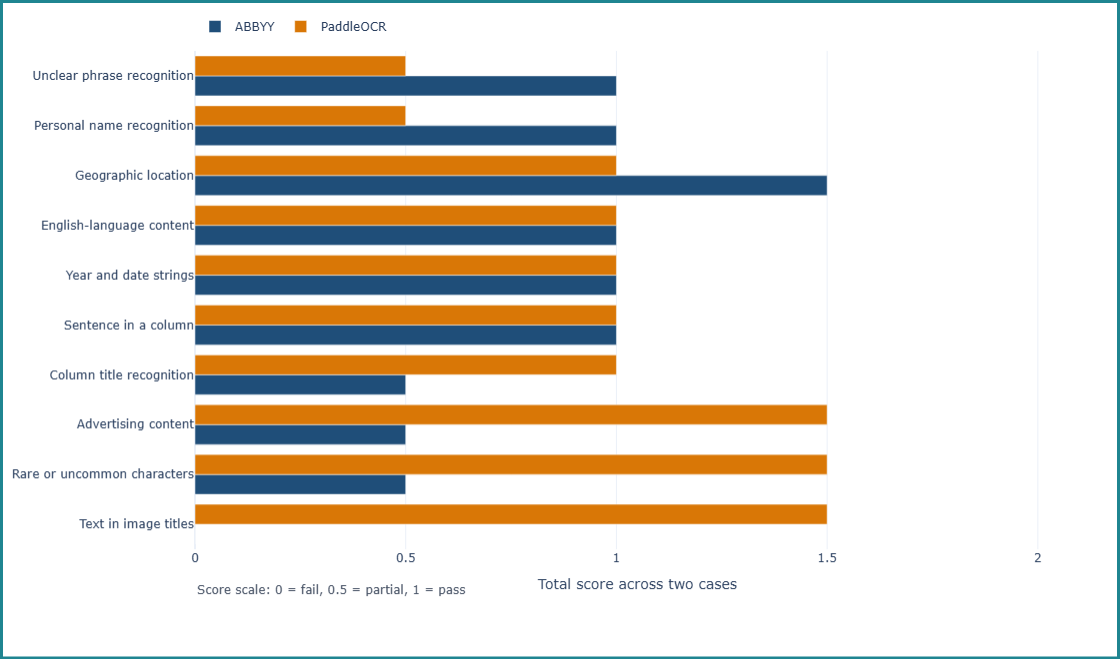
On the other hand, ABBYY is able to detect more words than Paddle, and can still return correct text output even when the print is unclear. ABBYY is also able to accurately detect certain rarely used or obsolete characters (such as “囘”). In contrast, Paddle tends to discard unclear or poorly recognized words to enhance sentence readability. As a result, the recognized sentences contain very few illegible words, but only because many of these unrecognized words have been dropped. This poses a challenge when performing keyword searches in the search platform used by the Canadiana and Héritage websites.
It’s important to note that ABBYY does not perform single-step OCR processing: its full pipeline includes pre-processing images, OCR, and final spelling and layout correction. To replicate the quality of its results with Paddle, setup is required for each stage in the process, and different processes may be required for different types of documents. It is up to each institution to choose the approach that will work best for a given set of documents and its level of expertise with OCR processing. At CRKN, significant time was spent between Mary, John, and Brittny to find the right combination of models and techniques that would produce successful results.
To learn more about CRKN’s OCR assessment work from a technical standpoint, visit our OCR evaluation repo, which contains additional test data, information about OCR pipelines, and tips on getting the most out of OCR processing.
Next Steps
Overall, Paddle demonstrates strong alignment with CRKN’s requirements in layout analysis and text structure clarity, making it especially suitable for processing historical newspapers and Chinese-language materials. However, as we learned during our assessment, different OCR tools have different strengths and can be applied to different use cases.
Following the success of our initial experiments with Paddle and the Chinese Times, CRKN is currently planning an open-source OCR and HTR (handwritten text recognition) system that will support large-scale, high-quality text recognition for the Canadiana and Héritage Collections. This system, which will include a variety of OCR and HTR models available as plugins, will enable entire collections to be processed efficiently and accurately. CRKN staff are also exploring leading-edge academic research on automating OCR and HTR evaluation, which will reduce manual checks and select the best tool for each type of document automatically.
To stay in the loop, be sure to check back soon for more articles about OCR assessment and experimentation at the CRKN Knowledge Exchange.

Francesca Brzezicki https://orcid.org/0009-0005-0744-715X
Francesca Brzezicki joined CRKN in 2019 and holds a Master's degree in Public History from Carleton University. You can contact her at fbrzezicki@crkn.ca.

Mary Zheng
Mary holds a Master's degree in Applied Computing from Windsor University and has over ten years of programming experience spanning various business sectors. She is passionate about developing industry applications.